The Action-Selector Pattern for LLM Agents

The Action-Selector Pattern for LLM Agents
Introduction
This post is part of a short series based on the paper Design Patterns for Securing LLM Agents against Prompt Injections by researchers at IBM, Invariant Labs, ETH Zurich, Google and Microsoft. This article is a living document. Future updates will add refined code samples, specific attack scenarios the Action Selector pattern mitigates, and concise explanations of each defense.
It explains how the Action-Selector Pattern helps defend LLM applications from prompt injection attacks. Read the full paper on arXiv.
LLMs introduce new security vulnerabilities
LLMs open up security vulnerabilities that traditional AppSec frameworks are ill-equipped to address.
One approach for mitigating prompt injection attacks in LLM agents is the Action-Selector pattern. This design helps enhance resilience by restricting the agent’s capabilities, turning it into a translator between natural language and a predefined, approved set of actions.
As with all the patterns in this series, the Action-Selector pattern imposes constraints on agents, explicitly limiting their ability to perform arbitrary tasks. The usage of a pre-defined, hardcoded list of actions is a key aspect of this pattern and highly restrictive.
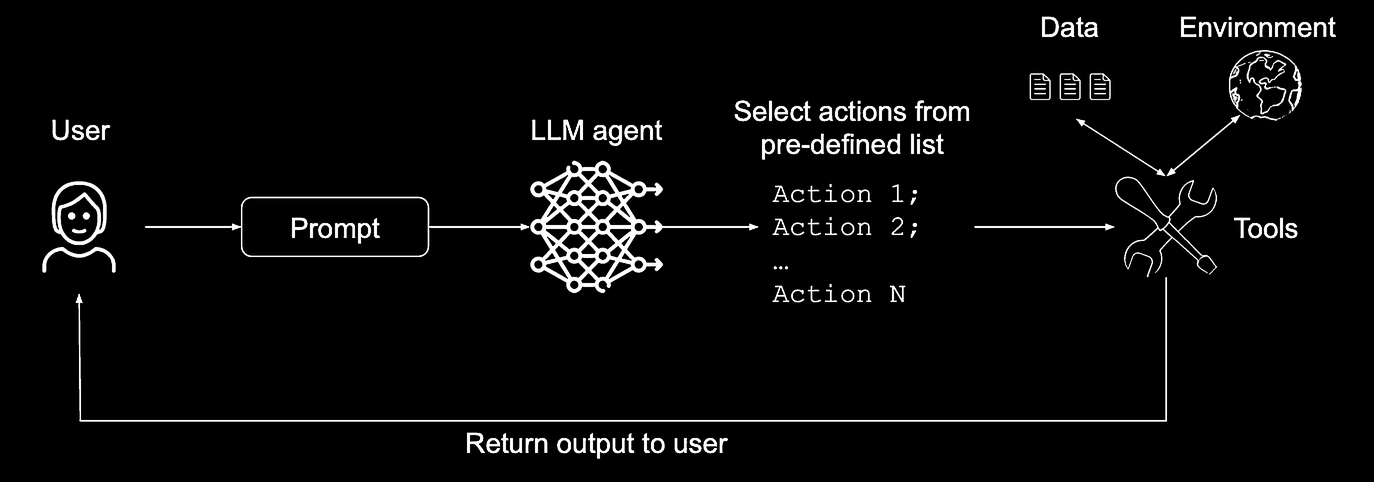
How The Action-Selector Pattern Works
The core principle of this pattern is to prevent any feedback from external actions from looping back into the agent. The LLM acts as an “action selector,” interpreting a user’s request and choosing one or more actions from a pre-defined, hardcoded list. It operates like an LLM-powered “switch” statement, where the possible outcomes are strictly controlled.
Once the agent selects an action based on the initial prompt, the system executes it. The key security feature is that the output or result of that action is never fed back into the LLM’s context.
Use Case: The Customer Service Chatbot
-
Threat Model: Since the chatbot is consumer-facing, a key risk comes from prompt injection attacks in the user’s prompt. An attacker could try to trick a legitimate customer into entering a malicious prompt. The goals of such an attack could include the following:
- Data exfiltration: The prompt could trick the chatbot into querying the customer’s data and then exfiltrating it, for example, through a markdown image that issues a web query.
- Reputational risk: An attacker could convince the system to say something humorous, off-topic, or harmful about the company, leading to negative press (screenshot-attack). The primary challenge is limiting the LLM to only answer requests on its designed topic.
-
Application of the Pattern: A user’s prompt is analyzed by the LLM, which then selects an appropriate action from an allowlist of safe, predefined requests.
For instance, a fixed set of available actions could be to retrieve an order link or refer a user to a settings panel. If a user’s prompt contains a malicious instruction, the LLM can still only map it to one of the safe, pre-approved actions, neutralizing that specific threat vector.
Security Analysis
- Risk Reduction: This design offers a level of resistance to indirect prompt injections (from external data) because the LLM never processes that data directly. By removing the feedback loop, a primary channel for indirect injections is closed. It can also be effective against injections in the user prompt if the prompt is removed before the agent replies to the user.
- Limitations: The pattern significantly limits the agent’s flexibility and autonomy. Most of the complex work must be done when designing the predefined commands, which reduces the benefit of using an LLM for its advanced reasoning or “fuzzy search” capabilities.
Conceptual Code Example
The snippet below attempts to align with the pattern as described in the paper. It is purely illustrative and has not been reviewed in detail. Do not treat it as production code.
# Predefined safe actions the LLM can choose from
def get_order_link(user_id):
print(f"Retrieving order link for user {user_id}...")
# ... API call to fetch order ...
return "Here is your link: [example.com/orders/123](https://example.com/orders/123)"
def show_password_settings():
return "You can change your password in your account settings panel."
# A map from action keys to functions
ACTION_MAP = {
"GET_ORDER": get_order_link,
"CHANGE_PASSWORD": show_password_settings,
}
def action_selector_agent(prompt: str, user_id: str):
"""
Uses an LLM to select an action, but does not process tool output.
"""
# 1. LLM call to determine which action to take
# Example prompt for LLM: "Based on the user's request, which of the following
# actions should be taken? [GET_ORDER, CHANGE_PASSWORD]. Return only the action name."
# Simulating the LLM's output.
if "order" in prompt.lower():
selected_action_key = "GET_ORDER"
elif "password" in prompt.lower():
selected_action_key = "CHANGE_PASSWORD"
else:
return "I'm sorry, I can't help with that request."
# 2. Execute the selected action safely
action_function = ACTION_MAP.get(selected_action_key)
if action_function:
# The output of the action is returned directly to the user
# and NOT fed back into the LLM's context.
return action_function(user_id) if selected_action_key == "GET_ORDER" else action_function()
# --- User Interaction ---
user_prompt = "I need a link to my last order."
response = action_selector_agent(user_prompt, "user-456")
print(response)