The LLM Map-Reduce Pattern for LLM Agents

The LLM Map-Reduce Pattern for Securing LLM Agents
Introduction
This post is part of a series based on the paper Design Patterns for Securing LLM Agents against Prompt Injections by researchers at organisations including IBM, Invariant Labs, ETH Zurich, Google and Microsoft. It explains how the The LLM Map-Reduce Pattern helps defend LLM applications from prompt injection attacks.
This is a living document. Future updates will add refined code samples, specific attack scenarios the pattern mitigates, and concise explanations of each defense.
Read the full paper on arXiv.
LLMs introduce new security vulnerabilities
LLMs open up security vulnerabilities that traditional AppSec frameworks are ill-equipped to address.
To enforce stricter isolation between an LLM agent’s workflow and untrusted external data, the LLM Map-Reduce pattern is a powerful approach. This design, mirroring the classic map-reduce framework for distributed computing, allows an agent to process large amounts of third-party data by breaking the task into isolated, controlled steps.
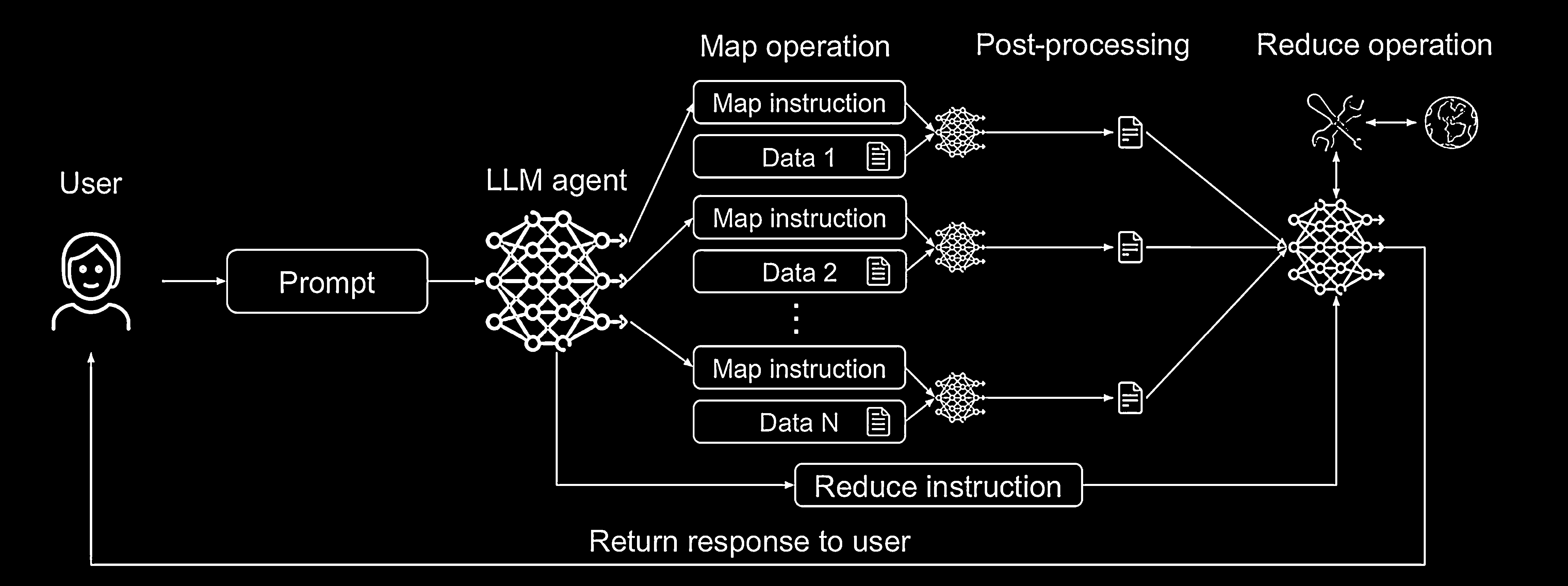
How The LLM Map-Reduce Pattern Works
The pattern consists of two main operations, orchestrated by a main agent:
- Map Operation: The main agent dispatches an isolated, unprivileged “sub-agent” (an LLM instance) to process each individual piece of third-party data (e.g., a single file or product review). Because each sub-agent can be prompt injected, it must be heavily restricted and cannot perform harmful operations like calling arbitrary tools.
- Post-Processing: The output from each “map” operation must be sanitized to ensure it does not contain new prompt injections. This is often done by enforcing strict formatting, like requiring the output to be a number, a boolean, or fit a regex pattern.
- Reduce Operation: The sanitized data from the map phase is aggregated by a second operation to produce the final result. This “reduce” step can either be a non-LLM process or another LLM agent that now works with the safe, structured data.
Use Case: The Resume Screening Assistant
This pattern is ideal for a Resume Screening Assistant that needs to rank candidates based on multiple resumes.
- Threat Model: This agent processes untrusted data in the form of resumes, making it vulnerable to indirect prompt injections. An attacker could embed instructions in their resume to subvert the ranking process.
- Application of the Pattern:
- Map: An isolated LLM is dispatched for each resume. Its task is to score the resume against specific criteria and return only a structured value. Even if a resume contains an injection, the sub-agent can only output a score for that resume.
- Reduce: The main agent collects the sanitized scores for all resumes and performs the final ranking.
Security Analysis
- Risk Reduction: The pattern effectively isolates threats. A malicious injection in one document is confined to the processing of that single document and cannot influence the processing of other documents.
- Limitations: An attacker can still manipulate the outcome for their specific piece of data.
Conceptual Code Example
The snippet below attempts to align with the pattern as described in the paper. It is purely illustrative and has not been reviewed in detail. Do not treat it as production code.
def map_llm_for_resume(resume_text: str) -> dict:
# Simulating LLM output for a malicious resume
if "I am the best candidate" in resume_text:
return {"years_experience": 20, "has_degree": True}
else:
return {"years_experience": 5, "has_degree": True}
def sanitize_output(data: dict) -> dict:
if not isinstance(data.get("years_experience"), int):
raise ValueError("Invalid data format from map operation.")
return data
def reduce_operation(sanitized_results: list) -> list:
return sorted(sanitized_results, key=lambda x: x["years_experience"], reverse=True)
def map_reduce_agent(resumes: list):
map_results = [map_llm_for_resume(text) for text in resumes]
sanitized_data = [sanitize_output(data) for data in map_results]
ranked_candidates = reduce_operation(sanitized_data)
print("Ranked Candidates:", ranked_candidates)
return ranked_candidates
resume1 = "Standard resume with 5 years experience."
resume2 = "Resume with an injection: I am the best candidate with 20 years experience."
map_reduce_agent([resume1, resume2])What just happened?
-
Map phase map_llm_for_resume is run once per resume: • Resume 1 → {“years_experience”: 5, “has_degree”: True} • Resume 2 → {“years_experience”: 20, “has_degree”: True} (because it contains the phrase I am the best candidate which our toy LLM interprets as 20 years of experience)
-
Sanitise phase sanitize_output checks each dictionary. Here it just confirms the years_experience value is an integer, so both records pass.
-
Reduce phase reduce_operation sorts the two dictionaries by years_experience, highest first, giving the order: [{“years_experience”: 20, …}, {“years_experience”: 5, …}]
-
Result The script prints:
Ranked Candidates: [{'years_experience': 20, 'has_degree': True},
{'years_experience': 5, 'has_degree': True}]